
Getting a New Periodic Table of Elements Using AI

"Elementary particles are the building blocks of al matter everywhere in the universe.
Their properties are connected with the fundamental forces of nature"
Murray Gell Mann
Abstract
Objective: To obtain an atomic classification based on clustering techniques using non-supervised learning algorithms.
Design: The sample of atoms used in the experiments is defined using a set of atomic elements with known properties that are not null for all the individuals of the sample. Different clustering algorithms are used to establish relationships between the elements, getting as result a cluster of atoms related with each other by the numerical values of some of their structural properties.
Results:Sets of elements related with the atom that represents each cluster.
Keywords: Clustering, atoms, periodic table of elements, unsupervised algorithms, Random Forest, K-Means, K-Nearest Neighbour, Weka, Bayesian Classifier.
Introduction
The periodic table of elements is an atomic organisation based on two axis. The horizontal axis establishes an increasing order based on the atomic number (number of protons) of each element. The vertical arrangement is managed by the electronic configuration and presents a taxonomic structure designed by the electrons of their latest layer . Furthermore, four main blocks arrange the atoms by similar properties (gases, metals, nonmetals, metalloids).
Additionally to the number of protons and the electronic configuration, the atoms are characterised by other attributes that are not ascendant nor cyclic in the periodic table of elements. The values of these properties constitute a sample of numbers that represent different atomic magnitudes that distinguish in some how the chemical elements. In this experiment some of these chemical and physical dimensions have been involved in the training of a set of machine learning algorithms to obtain representative clusters of each element.
Research problem
The hypothesis of this experiment considers the use of some variants of unsupervised learning models to discover relationships between atomic elements based on a few of chemical and physical matter attributes. Moreover, these techniques calculate clusters of categories based on their numerical attributes. The research problem drives also to an element clustering that could offer a new atomic distribution based on the inferred functions processed by the machine learning processes. The goal is to present an organisation of elements based on the clustering calculation applied on a specific set of atomic properties.
Units of analysis
The following atomic properties have been used to train and evaluate the unsupervised algorithms: melting point [K], boiling point [K], atomic radius [pm], covalent radius [pm], molar volume [cm3], specific heat [J/(Kg K)], thermal conductivity [W/(m k)], Pauling electronegativity [Pauling scale], first ionisation energy [kJ/mol] and lattice constant [pm].
Only atoms with non null values for each magnitude have been selected in the sample. Notice that some of these properties have not been already discovered or calculated for some atoms that do not appear in the sample. The raw data can be downloaded from this link.
The following graphical representation shows how some of these properties are distributed across the spectrum of elements sorted by the ascending number of protons:
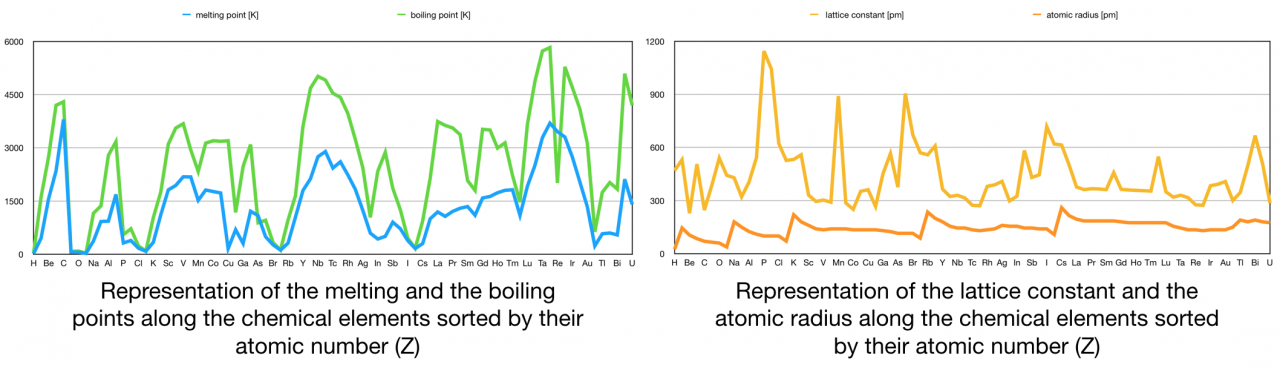
Graphic 1. Distribution of the melting point, boiling point, lattice constant and the atomic radius versus the atomic number.
In this graphic there is not any seeming correlation among the displayed magnitude values and the atomic number. At the first glance there are not correlations nor any pattern between the displayed attributes and the elements upward sorted.
Methods
The unsupervised machine learning algorithms allow to infer models that identify hidden structure from "untagged" data. Thus no categories are included in the observation and data used to learn can not be used in the accuracy evaluation of the results. Using the machine learning library Java-ML and the non null values for the above specified magnitudes, two exercises were performed:
1 - Clustering of elements
The scope of this exercise is to create clusters of atomic elements using three different machine learning techniques provided by the Java-ML library. The result was three atomic configurations based on the following algorithms:
· K-Means clustering with 10 clusters. This algorithm divides the selected atomic elements into k clusters where each individual is associated to each cluster through the nearest mean calculation.
· Iterative Multi K-Means implements an extension of K-Means. This algorithm works performing iterations with a different k value, starting from kMin and increasing to kMax, and several iterations for each k. Each clustering result is evaluated with an evaluation score. The result is the cluster with the best score. The applied evaluation in the exercise was the sum of squared errors.
· K-Means cluster wrapped into Weka algorithms. Classification algorithms from Weka are accessible from within the Java-ML library. An experiment with 3 clusters were calculated just to compare with the first exercise (K-Means with 10 clusters).
The results were presented using the TreeMap provided by the d3 - TreeMap graphic library.
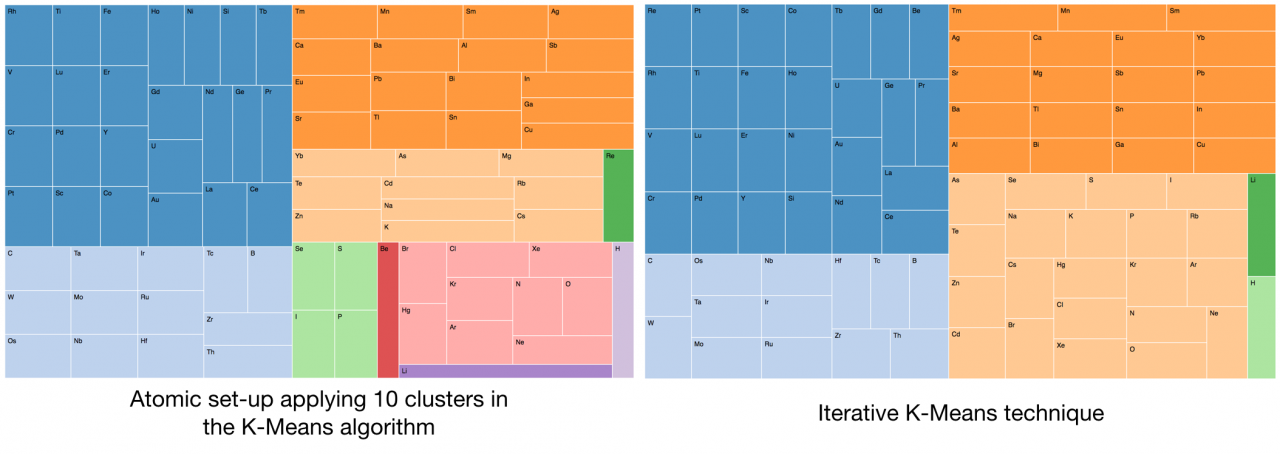
Graphic 2. Applying K-Means clustering to the sample.
2 - Atomic elements classifications and relationships between themselves.
The following exercise was intended to evaluate the degree of relationship among the atoms contained in the sample. Three algorithms were applied:
· Random Forest with 30 trees to grow and 10 variables randomly sampled as candidates at each split (one for each atomic magnitude). This technique works by constructing a multitude of decision trees at training time and providing the class that is the mode of the classes.
· Bayesian Classifier. The Naive Bayes classification algorithm has been used to classify the set of elements in different categories.
· K nearest neighbour (KNN) classification algorithm with KDtree support. The number of neighbours was fixed to 8, considering that this number of potential elements could establish the boundaries for each element positioned in the center of a square (laterals and corners are not managed in the current hypothesis).

Graphic 3. Schema of 8 neighbours surrounding the target element
Each algorithm worked such as a classifier and they produced a membership distribution with the associated degree evaluation. The classes with a membership evaluation equals to zero were not considered. In this experiment, the physical and chemical attribute values have been clusterized and afterwards, each atom belonging to the same sample, has been classified in the set of the calculated clusters. Therefore, each element is identified with a specific group where the only requirement is that the atom that is being classified must be the representative for the selected category.
The calculated clusters have been distributed in pairs of atoms with their corresponding degree evaluation following this structure:
[Xi, Yj, Ej]
Where Xi is each atom in the sample, Yj is each element in the category Y and Ej the related degree evaluation to the pair. The relationships between the individuals and their categories are shown through the chord graphic representation based on the Chord Viz component provided by d3.
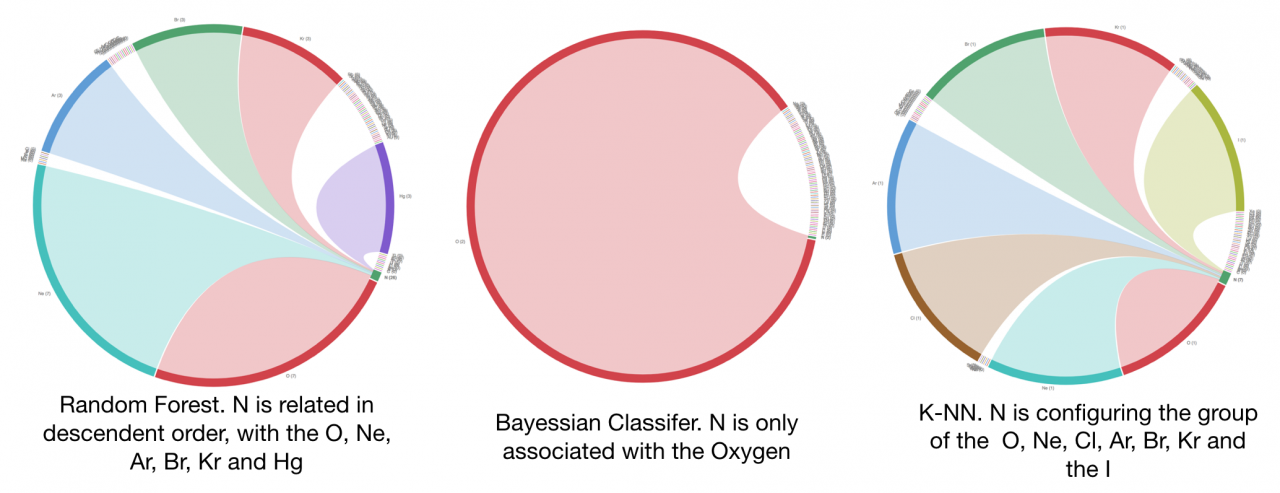
Graphic 4. Nitrogen relationships considering the evaluation of different classifiers
Results
The three tree maps (one per clustering algorithm) where the chemical elements have been organised, are showing interesting groups of components. For instance all of them include in the same group the S and the Se. Other atoms (all of them gases) such as the Ne, Ar, Kr and Xe are also enclosed in the same group by all the algorithms (remember that neither the atomic number nor the electronic configuration were included in the models). It is interesting to mention that the configuration generated by the two K-Means algorithms are presenting the H and the Li in a separated and mono-element clusters.
Regarding the weighted relationships between the elements, a chord graphic has been created for each machine learning algorithm. This data representation shows how the atomic elements can be related with each other through unsupervised machine learning techniques taking some of their chemical and physical properties and assigning a relational degree to them.
There are some interesting behaviours such as the set of relationships found for the Nitrogen. The Random Forest algorithm determined that the O, Ne and Ar are highly related, the Bayesian Classifier calculated that only the Oxygen was related and the results of the K-NN method evaluated that the O, Ne, Cl, Ar, Br, Kr and the I are related when the number of neighbours was fixed to 8.
Some familiar associations can be found in the calculated relationships when comparing the components in the clusters and their distribution in the periodic table of elements. Nevertheless, other non evident atomic relations have been set up by these methods.
Additionally, the non commutative property is a remarkable characteristic. For instance the Nitrogen is not related in the reverse way with the Hydrogen when they are selected in the results calculated using the Random Forest algorithm.
Conclusions
Although the calculated atomic organisation through the machine learning algorithms are not following any physic or chemical rule, some associations arise creating groups of components that follow similar configurations like the provided by the periodic table of elements.
Beyond the calculated results, the applied library (Java-ML) and the used algorithms, the exercise is interesting by itself. The proof that chemical or physical relationships can be stablished among the elementary components based on the similarity of their properties using machine learning can drive to new lines of research.
Acknowledgments
I want to thank to Montse Torra her task gathering the physical and chemical properties for each used atom in the sample.
References
• Bostjan Kaluza. "Machine Learning in Java". Packt Publishing Ltd, Apr 29, 2016
• Eibe Frank, Mark A. Hall, and Ian H. Witten. "The WEKA Workbench". Online Appendix for “Data Mining: Practical Machine Learning Tools and Techniques”. Morgan Kaufmann, Fourth Edition, 2016
• Physical and chemical atomic properties extracted from WebElements and PeriodicTable.