
Apache Flink - Distributed Stream and Batch Data Processing
On 26 May, 2016 By Michael.Walker 0 Comments

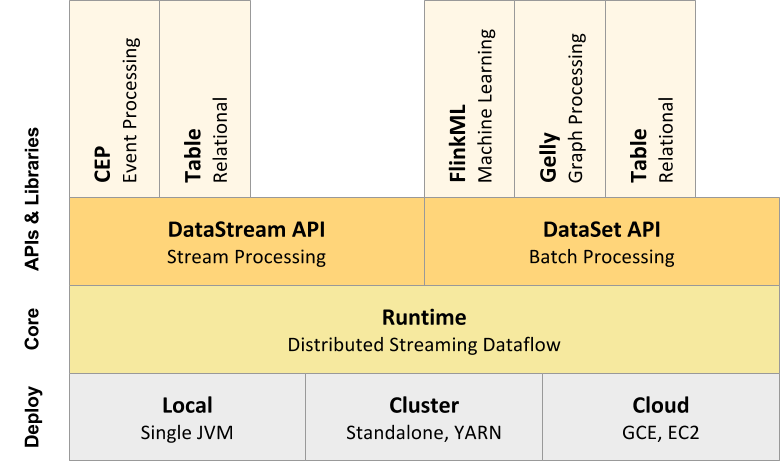
Flink is an open source platform for distributed stream and batch data processing. Fast, general purpose distributed data processing system that combines batch and stream processing. Up to 100x faster than
Hadoop Mapreduce.
Flink’s core is a streaming dataflow engine that provides data distribution, communication, and fault tolerance for distributed computations over data streams. Key features:
- Batch and stream processing in the same system
- No micro-batches, unified runtime
- Code reusable from batch processing to streaming, making development and testing simple