
The Emerging Data Stack

The emerging "Data Stack" or "Data Layer" is in full transition and can be viewed and defined many different ways. The ability to capture, analyze and learn from data generated at unprecedented scale, combined with means to access that information, on demand, when relevant, creates business opportunities we are only just beginning to appreciate.
One way simply defines data in a three layer stack:
- Internal Data: The data gathered into a data warehouse from the transactional systems of a company.
- Contextual Data: The data from external sources that adds context to tell the whole story by adding spatial data, population, demographics, and so on.
- The Integrated Data Model: The metadata that ties everything together to support advanced analysis.
The top layer of the stack, internal data, is specific to an organization. The contextual layer comes from other sources. The integrated data model is for advanced data analytics applications.
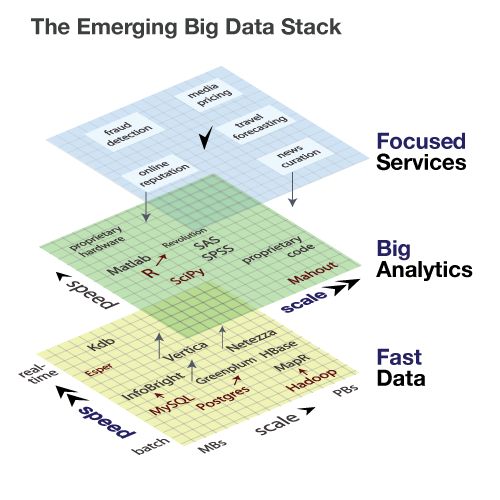
Another more complex way is represented in the above image:
As the foundational layer in the big data stack, speed kills along with scalable persistence and compute power. At the middle layer of the big data stack is analytics, where features are extracted from data, and fed into classification and prediction algorithms. At the top of the stack are services and applications. This is the level at which consumers experience a data product, whether it be a music recommendation or a traffic route prediction.
At the bottom tier of data, free tools are shown in red (MySQL, Postgres, Hadoop), and we see how their commercial adaptations (InfoBright, Greenplum, MapR) compete principally along the axis of speed; offering faster processing and query times. Several of these players are pushing up towards the second tier of the data stack, analytics. At this layer, the primary competitive axis is scale: few offerings can address terabyte-scale data sets, and those that do are typically proprietary. Finally, at the top layer of the big data stack lies the services that touch consumers and businesses. Here, focus within a specific sector, combined with depth that reaches downward into the analytics tier, is the defining competitive advantage.
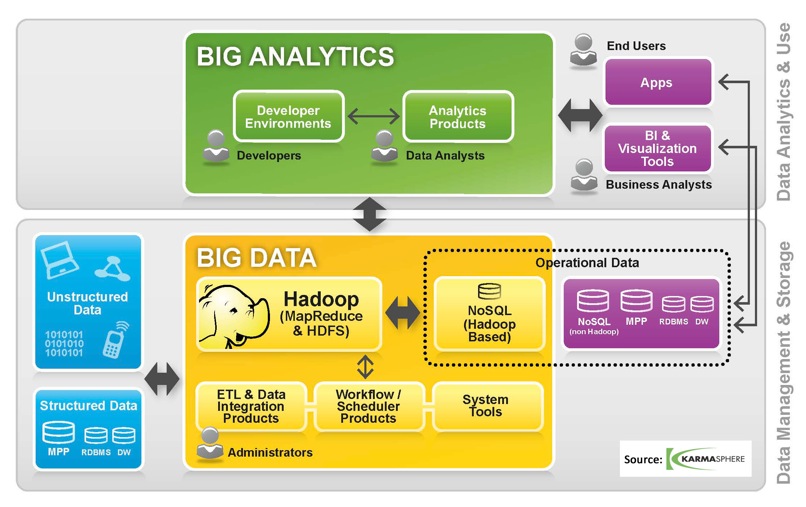
There are three data layer trends: data growth, web application user growth and the explosion of mobile computing.
Data growth [Big Data]. IDC estimates an organizations data will double every two years. Mining this raw data for valuable, actionable insights is challenging. Hadoop (HDFS, MapReduce, Cassandra and Hive) are batch-processing oriented and assist in analyzing large data sets.
User growth [NoSQL]. Most new interactive software systems are accessed via browser. If available on the public Internet, these applications now have 2 billion potential users and a 24x7 uptime requirement. Regardless of dataset size, these software systems put unprecedented pressure on the data layer: massive user concurrency; need for predictable, low-latency random access to data to maintain a snappy interactive user experience; and the need for continuous operations, even during database maintenance. Cassandra, Couchbase and MongoDB are among open source NoSQL technologies that meet the data management needs of interactive web applications.
Mobile computing growth [Mobile Sync]. Mobile devices are increasingly where we create and consume information. But data aggregation and processing will be accomplished in the cloud. IDC estimates that in 2015, 1.4 of the 4.9 zettabytes created that year will be "touched by the cloud." Delivering the right data to millions of mobile devices, when and where it is needed (and then getting it back again) is the mobile-cloud data sync challenge.
These three trends may constitute the future emerging modern data stack - one that supports the ebb and flow of information from web and mobile applications to the cloud.
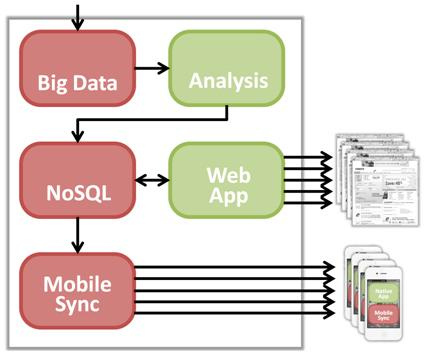
The key is to design and build a data warehouse / business intelligence (BI) architecture that provides a flexible, multi-faceted analytical ecosystem, optimized for efficient ingestion and analysis of large and diverse datasets.
Data comes from a variety of sources (internal, external, contextual, integrated): data directly created by users of web and mobile applications, observations and metadata related to the use of web and mobile applications, external data feeds, intermediate analysis results. The processing of this information creates information needed by user-facing applications and is fed into a NoSQL solution.
The NoSQL solution provides low-latency, random access to the data, meeting the needs of web applications. It also allows a mobile synchronization server quick, random access to data needed by mobile users.
A Mobile Sync Server manages transient connections with mobile devices, delivering data to native mobile applications when and where it is needed; and receiving information in return.