
Fooled by Twitter Data

Data scientists must always remember that data sets are not objective - they are selected, collected, filtered, structured and analyzed by human design. Naked and hidden biases in selecting, collecting, structuring and analyzing data present serious risks.
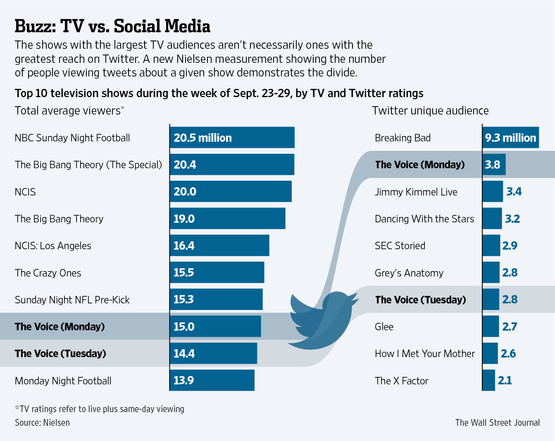
For example, a recent Wall Street Journal article entitled "Tweets Provide New Way to Gauge TV Audiences" provides evidence of a disconnect between mainstream viewers and folks who use Twitter. The chart above shows the disconnect between the most popular and most tweeted shows - the most tweeted show is not a top ten show.
While Twitter data can be useful for detecting trends and sentiments for certain areas (e.g., disease surveillance, natural disaster surveillance, product sentiments, financial trading, politics) in limited circumstances using scientific methods, it can also mislead and present a false view of reality.
At this time, Twitter demographics do not mirror the population as a whole. The number of folks tweeting about a subject can be small yet vocal and that is problematic when attempting to interpret data and evidence. Data scientists need to avoid the following data science sins when interpreting data:
1. Sampling bias: systematic error due to a non-random sample of a population, causing some members of the population to be less likely to be included than others, resulting in a biased sample - skewing the sampling of data sets toward subgroups of the population most relevant to the initial scope of data science project, thereby making it unlikely that you will uncover any meaningful correlations that may apply to other segments.
2. Data Dredging bias: using regression techniques that may find correlations in small or some samples - but that may not be statistically significant in the wider population.
3. Data selection bias: skewing selection of data sources to most available, convenient and cost-effective, in contrast to being most valid and relevant for specific study. Data scientists have budget, data source and time limits - and thus may introduce unconscious bias in data sets able to select and those excluded.
The Twitter data lesson is that data scientists need to be scrupulous about using the scientific method when interpreting data and evidence to avoid creating an illusion of reality and thus causing consumers of data science to potentially make bad decisions.