
Four Reasons for Immutable HDFS Archive

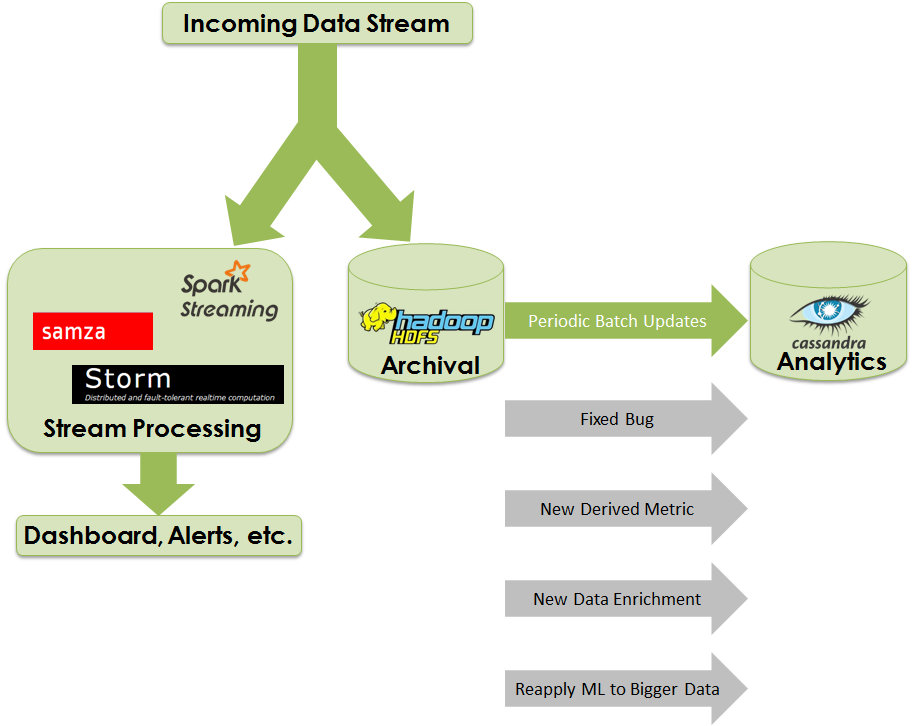
Two years ago, when I first joined Michael Walker's Data Science & Business Analytics Meetup, the form asked (and still asks) "What important truth do very few people agree with you on?" My answer was "Data should never be deleted". At the time, I had no idea what Data Science was and had barely been introduced to Big Data, but it was a dictum I lived by, much to the consternation of my bosses over the past two decades when it came time to approve purchases of hard drives.
Well, I may have to update my profile, because it seems more and more people are agreeing with me. As I blogged on the January, 2014 Boulder/Denver Big Data Meetup, the discussion format came to a consensus that all ingested data should be kept intact as-is as an immutable data store, and that processed data should be stored in some kind of data warehouse for the actual analytics. I wrote then that it was good to have that pattern, which was in the making for a couple of years, finally codified as a pattern.
It's even more solidified now. The two most common motivations given are:
1. Bugs
You might discover a bug in your processing code, and so you may need to reprocess all the original data with the corrected code.
2. New Derived Metric
You might discover you need to track clicks per second rather than just clicks per minute. With the original data still around, it becomes possible to resummarize the raw data.
Two Other Reasons
But here are two other reasons, not usually stated when this pattern is presented:
3. New Data Enrichment
Suppose in your summarized data you don't store social security number even though it exists in the original data. Then your company just obtained the services of data provider, and you're now able to get household income based on social security number. Now you can append this data as another column in the analytics database.
4. Reapply Machine Learning to Bigger Data Set
This is perhaps the most important reason of all, due to the The Unreasonable Effectiveness of Data. As more data becomes available over time from the original data streaming source, machine-learned models can be improved.