
Lambda Architecture for Big Data Systems

Big data analytical ecosystem architecture is in early stages of development. Unlike traditional data warehouse / business intelligence (DW/BI) architecture which is designed for structured, internal data, big data systems work with raw unstructured and semi-structured data as well as internal and external data sources. Additionally, organizations may need both batch and (near) real-time data processing capabilities from big data systems.
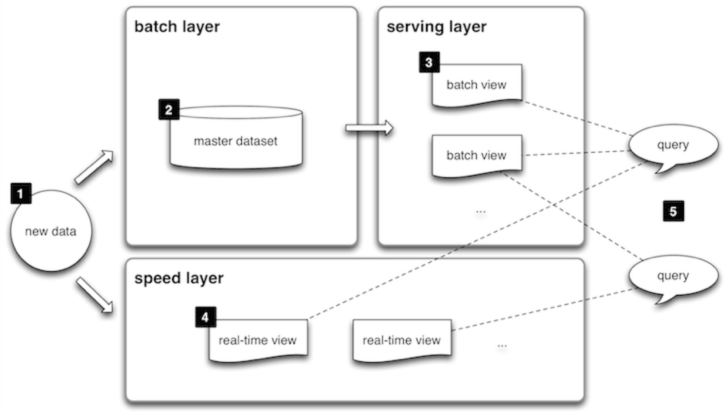
Lambda architecture - developed by Nathan Marz - provides a clear set of architecture principles that allows both batch and real-time or stream data processing to work together while building immutability and recomputation into the system. Batch processes high volumes of data where a group of transactions is collected over a period of time. Data is collected, entered, processed and then batch results produced. Batch processing requires separate programs for input, process and output. An example is payroll and billing systems. In contrast, real-time data processing involves a continual input, process and output of data. Data must be processed in a small time period (or near real-time). Customer services and bank ATMs are examples.
Lambda architecture has three (3) layers:
- Batch Layer
- Serving Layer
- Speed Layer
Batch Layer (Apache Hadoop)
Hadoop is an open source platform for storing massive amounts of data. Lambda architecture provides "human fault-tolerance" which allows simple data deletion (to remedy human error) where the views are recomputed (immutability and recomputation).
The batch layer stores the master data set (HDFS) and computes arbitrary views (MapReduce). Computing views is continuous: new data is aggregated into views when recomputed during MapReduce iterations. Views are computed from the entire data set and the batch layer does not update views frequently resulting in latency.
Serving Layer (Real-time Queries)
The serving layer indexes and exposes precomputed views to be queried in ad hoc with low latency. Open source real-time Hadoop query implementations like Cloudera Impala, Hortonworks Stinger, Dremel (Apache Drill) and Spark Shark can query the views immediately. Hadoop can store and process large data sets and these tools can query data fast. At this time Spark Shark outperforms considering in-memory capabilities and has greater flexibility for Machine Learning functions.
Note that MapReduce is high latency and a speed layer is needed for real-time.
Speed Layer (Distributed Stream Processing)
The speed layer compensates for batch layer high latency by computing real-time views in distributed stream processing open source solutions like Storm and S4. They provide:
- Stream processing
- Distributed continuous computation
- Fault tolerance
- Modular design
In the speed layer real-time views are incremented when new data received. Lambda architecture provides "complexity isolation" where real-time views are transient and can be discarded allowing the most complex part to be moved into the layer with temporary results.
The decision to implement Lambda architecture depends on need for real-time data processing and human fault-tolerance. There are significant benefits from immutability and human fault-tolerance as well as precomputation and recomputation.
Lambda implementation issues include finding the talent to build a scalable batch processing layer. At this time there is a shortage of professionals with the expertise and experience to work with Hadoop, MapReduce, HDFS, HBase, Pig, Hive, Cascading, Scalding, Storm, Spark Shark and other new technologies.
Comments
mikepluta
Mon, 2014/03/24 - 9:27am
Permalink
Lambda Big Data Architecture Implementation Issues
In addition to the challenge of finding competent resources to build and operate a scaleable batch layer, the serving layer is a custom, purpose built piece requiring scarce resources.
Further, if there is a requirement to use COTS query and visualization tools, the components used to implement the speed and serving layers need to be carefully considered and coordinated. If the serving layer is required to be queried in parallel with the speed layer via a COTS tool, an additional layer to broker and manage the distribution of queries and union of results may be required.