
Rise of Data Anarchy: Structured vs. Raw Unstructured Data

Data science and business analytics works with both structured and raw unstructured data. Yet the future belongs to raw unstructured or semi-structured data from both internal and external sources - increasingly delivered in (near) real-time.
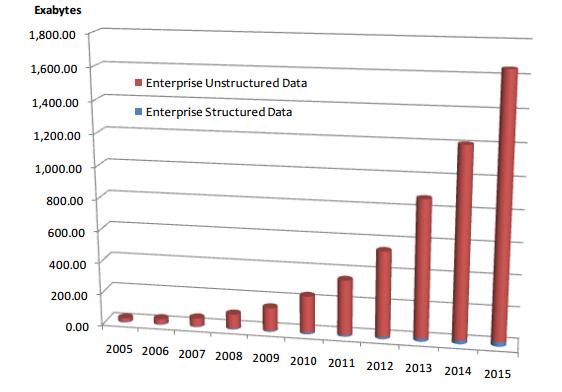
IDC estimates the volume of digital data will grow 40% to 50% per year. By 2020, IDC predicts the number will have reached 40,000 EB, or 40 Zettabytes (ZB). The world’s information is doubling every two years. By 2020 the world will generate 50 times the amount of information and 75 times the number of information containers.
The massive growth of unstructured or semi-structured data is amazing and has implications for data warehouse / business intelligence / data analytics architecture and database design. The way we capture, store, analyze, and distribute data is transforming. New technologies like deduplication, compression, and analysis tools are lowering costs.
Structured data gives names to each field in a database and defines the relationships between the fields. Raw unstructured data is usually not stored in a relational database (as traditionally defined) where the data model is relevant to the meaning of the data.
The Internet of Things (equipping all objects in the world with identifying devices), blogs, videos, social media, emails, notes from call centers, and all forms of human and computer to computer communications will soon start to produce massive amounts of raw unstructured or semi-structured data. This data has great value yet most organizations do not have the tech infrastructure to handle all this data.
The trick is to create value by extracting the right information from both internal and external data sources. That is what the science of data and art of business analytics needs to learn to extract from larger and larger sets of raw unstructured data.