
Spark 1.6: "Datasets" best of RDDs and Dataframes

 If
If
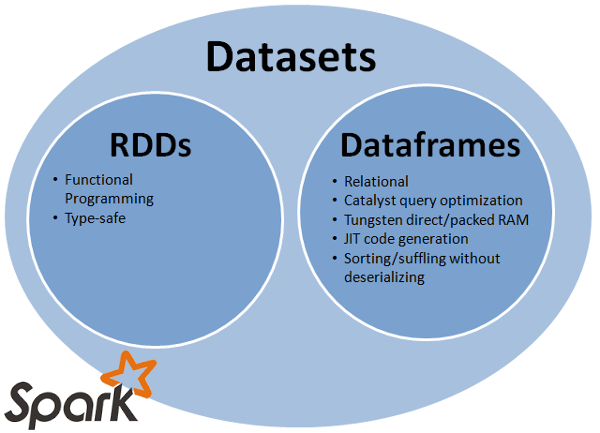
If RDDs weren't killed by Dataframes in Spark 1.3 (as covered by my January, 2015 blog post Spark 1.3: Stop Using RDDs), surely they will be by Spark 1.6, which introduces Datasets.
As covered in Michael Armbrust's presentation today at Spark Summit Europe 2015, Spark Dataframes: Simple and Fast Analysis of Structured Data, specifically in his last slide, Datasets (as originally proposed in the umbrella Jira ticket SPARK-9999) combine the best of both worlds of RDDs and Dataframes.
Datasets provide an RDD-like API, but with all the performance advantages given by Catalyst and Tungsten. groupBy(), for example, which was always a performance no-no on RDDs, can be done efficiently with Datasets without worrying for example about some groups being too large for a single node because Catalyst can spill large groups. And it's all strongly typed and type-safe.
Datasets will be previewed in Spark 1.6, due out in December.