
Structured Streaming for Lambda Architecture in Spark But Have To Wait For It

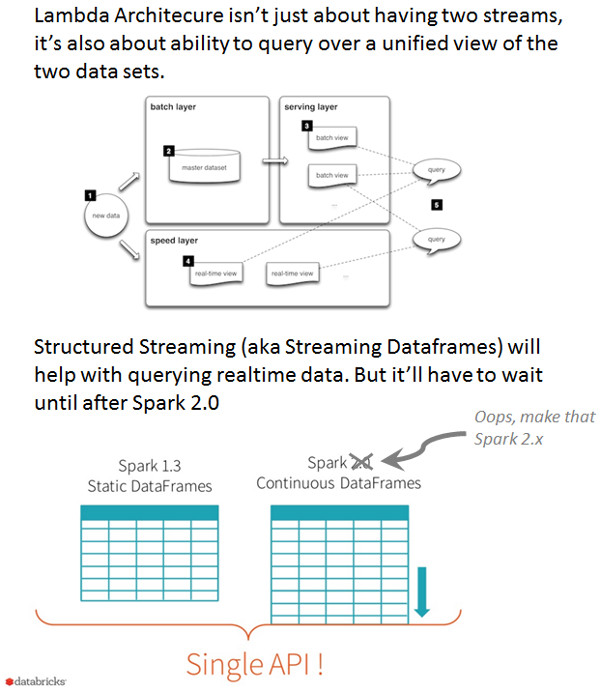
Image credits: lambda-architecture.net and Michael Armbrust's Spark Summit East presentation.
Some have the misconception that Lambda Architecture just means you have separate paths for batch and realtime. They miss a key part of Lambda Architecture: the ability to query a unified view of both batch and realtime.
Structured Streaming, also known as Structured Dataframes, will provide a critical piece: the ability to stream directly into a Dataframe, which can then of course be queried with SQL.
To provide the unified view, it will probably be possible to join such a Streaming Dataframe containing the realtime data with an ORC-backed Dataframe containing the historical data. However, as of today (May 14, 2016), the only two data sources available to populate a Streaming Dataframe are memory and file. Notably absent are streaming sources such as Apache Kafka, and last week Michael Armbrust indicated support for non-file data sources might come after Spark 2.0. And then this week Reynold Xin advised:
stay tuned to this blog for more details on Structured Streaming in Spark 2.0, including details on what is possible in this release and what is on the roadmap for the near future
There are still key adds in Spark 2.0: full SQL support including subqueries, and yet another 10x performance improvement due to "Tungsten 2.0" (on top of the 2x-10x improvement Tungsten brought over Spark 1.4, 1.5, and 1.6). Currently, Druid is still the reigning champ when it comes to Lambda in a Box. But Spark will likely take that crown before the end of this year.