
Visualization of How Real-time Cardinality Algorithms Work

In a previous blog post, Real-time data science, I textually described an algorithm that can be used, for example, in real-time data streaming applications to estimate the size (cardinality) of a set.
I don't think a description can convey how it works as well as a visualization, so I created an iPython Notebook. Below are the images from that Notebook, but you'll need to click on the Notebook link if you want to see how the images were generated and the detailed description.
As I described in the previous blog post, the motivation behind trying to count items in a data stream might be, for example, doing the equivalent of a SQL COUNT DISTINCT on a website's clickstream to get the number of unique visitors to that website.
Rather than maintaining in memory a list of unique ID's (say, IP addresses), which can consume a lot of memory for a popular website, instead we rely on a hash function and just keep track of the minimum hash value ever seen. That's right, instead of saving n IP addresses (where n might be a million for a very popular website), we just save one data value, the smallest hash value ever seen.
The scatter plot below shows the result. For the top dotted row, 10 random UUID's were hashed to floating point values in the range [0,1). For the middle row, 100 UUID's and for the bottom row, 1000 UUID's. Then we just count the number of leading zeroes of the smallest hash value by using the log10 function. To get the cardinality we just then raise 10 to the power of that number of leading zeros.
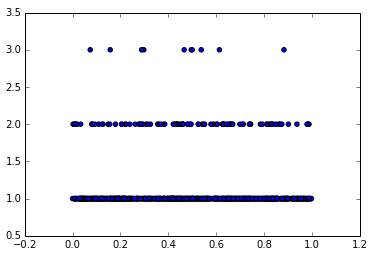
And zooming in to the left portion of the plot:
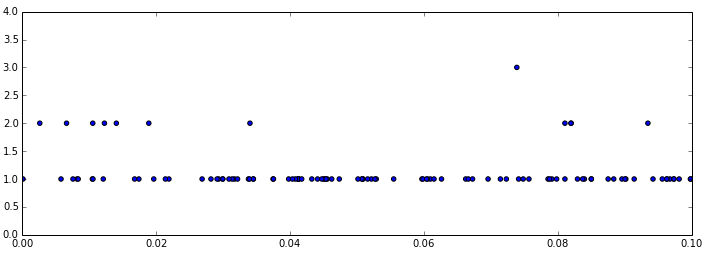
The larger the set, the greater the chance that a hash value will happen to end up closer to zero (left edge of the plot). To get the size of the set, we just count the number of leading zeros, and then raise 10 to the power of that number.
That leaves a lot to chance, of course, so there are ways to reduce the effects of randomness and improve the accuracy. One straightforward way, described in my iPython Notebook linked above, is to split the set into, say, 10 subsets, apply the algorithm to each subset independently, average the results somehow, and multiply that average by 10 to get the cardinality of the whole original set. So in terms of memory utilization, this approach requires the space of 10 floating point numbers instead of just 1.
In my iPython Notebook, I just do a simple straight average, and it does improve the accuracy significantly, but it's still off by a factor of 3 in the particular case I tried. A better way to average is a geometric mean. And best still is the HyperLogLog algorithm which employs something called the harmonic mean.
The bright folks over at Metamarkets, developers of Druid, ran some experiments two years ago and showed that HyperLogLog produces cardinalities that are 98% accurate.