
Anomaly Detection

The great Ted Dunning from MapR just today tweeted his Strata slides on Anomaly Detection from this first day of the Strata 2014 conference in Santa Clara. It's a subject not given enough attention in the Data Science community, especially with regards to real-time streaming time series data (aside from Andrew Weekley's presentation to the Data Science Association this past November, of course).
Ted Dunning's slides are an excellent and much needed simple introduction to the topic.
Amazon has several books on the subject:
The author, Victoria Hodge of the University of York, of the first book, Outlier and Anomaly Detection: A Survey of Outlier and Anomaly Detection Methods, also has a freely downloadable paper from 2004 (seven years before her book was published) that is also such a survey: A Survey of Outlier Detection Methodologies.
When multiple time series are available, rather than being a burden where each would be treated independently, they present an opportunity for even more intelligent opportunities for insight. In the slide below from a tutorial by Andrew Moore, CMU professor now at Google, he illustrates that rather than considering sales of cough medicine and emergency department visits as separate time series, scatter plot the two against each other and look for outliers there.
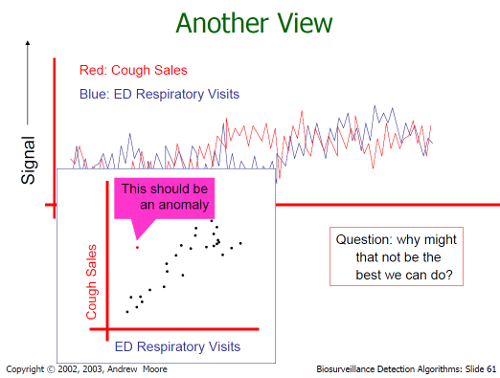
Then there is the philosophical question about to do about anomalies. Sometimes you're looking for them, but sometimes you want to throw them away. If you're looking for fault or fraud, you want to sound an alarm when the system detects an anomaly. On the other hand, sometimes you know from outside sources that an anomaly is caused by a faulty sensor or other data source, and you want to discard it so that you can perform statistical analysis and machine learning on the rest of the (good) data. Of course, throwing out too much or the wrong data runs the risk of missing out on potential valuable insights. But time is money, so you can't chase down every last anomaly.
Much of the literature is devoted to anomaly detection on networks, especially regarding intrusion detection. But in this new era of Big Data and streaming data (especially clickstreams, social media, and sensors) the need has grown for a broader class of anomaly detection systems and algorithms. There seems to be an opportunity for some canned R or iPython packages because while they both of course have machine learning packages, the available "outlier" packages for time series seem to just the simple statistical approaches that Ted Dunning's presentation explains doesn't catch seasonal effects. No available packages seem to specialize in machine learning patterns in one and many time series, including seasonal effects.