
Updated List of Spark Alternatives
On 5 Dec, 2014 By michaelmalak 0 Comments

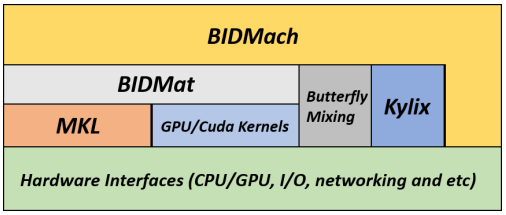
Eight months ago, I blogged a list of Spark alternatives. It's time to update that list:
Memory Based
- BID Data Project — Out of Berkeley (like Spark) but more recent, from 2013. I blogged about this project a couple of months ago, but I don't believe it's gotten the attention it deserves, and I believe it's the next big thing beyond Spark. The authors claim a single node with GPGPU is faster, when performing logistic regression, than a 100-node Spark cluster, although the Spark team notes that the comparison was against Spark 0.9 and that several improvements to Spark have since been made or are planned.
- Distributed R — A cluster computing version of the R programming language
- Parallel Processing in Python — A number of systems for cluster computing in the Python programming language (in addition to the one that Monte Lunacek presented last year)
- Apache Ignite (Open sourced by GridGain)
- Apache Flink (Formerly Stratosphere)
- H2O — Either stand-alone or integrated with Spark as Sparkling Water
- Piccolo
- RAMCloud
Disk Based
- HPCC
- Hadoop
- NoSQL