
Natural Language Processing: Tool for Computing Continuous Distributed Representations of Words

Natural language processing (NLP) involves machine learning, algorithms and linguistics related to interactions between computers and human languages. One important goal of NLP is to design and build software that will understand and analyze human languages to simplify and optimize human - computer communication.
NLP algorithms are usually based on probability theory and machine learning grounded in statistical inference — to automatically learn rules through analysis of real-world usage. It includes word and sentence tokenization, text classification and sentiment analysis, spelling correction, information extraction, parsing, meaning extraction, question answering and requires both syntactic and semantic analysis at various levels.
NLP applications today involve spelling and grammar correction in word processors, machine translation, sentiment analysis and email spam detection. NLP plus data science is now allowing us to design and implement better automatic question / answering systems and the ability to detect and predict human opinions about products or services.
Examples of NLP algorithms include n-gram language modeling, naive bayes and maxent classifiers, sequence models like Hidden Markov Models, probabilistic dependency and constituent parsing, and vector-space models of meaning.
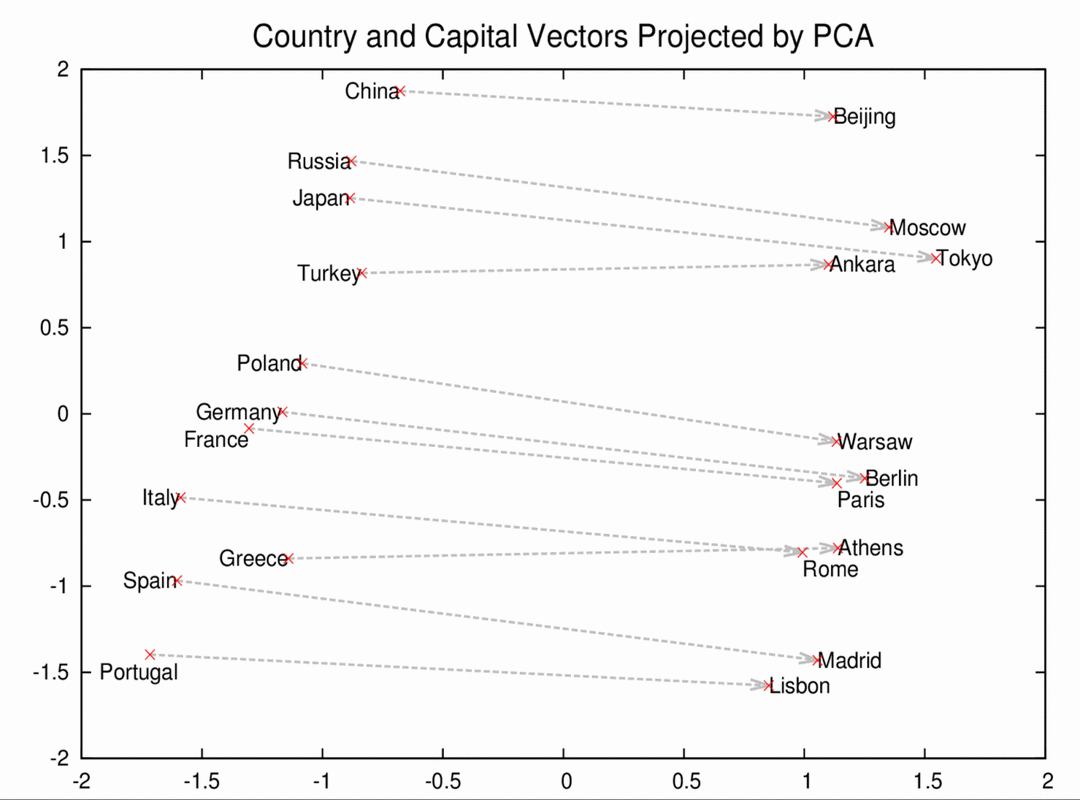
Google has open sourced a tool for computing continuous distributed representations of words that provides an efficient implementation of the continuous bag-of-words and skip-gram architectures for computing vector representations of words. These representations can be subsequently used in many natural language processing applications and for further research.
Download the code: svn checkout http://word2vec.googlecode.com/svn/trunk/
Run 'make' to compile word2vec tool
Run the demo scripts: ./demo-word.sh and ./demo-phrases.sh