
QED: Controlling for Confounders

We see it all the time when reading scientific papers, "controlling for confounding variables," but how do they do it? The term "quasi-experimental design" is unknown even to many who today call themselves "data scientists." College curricula exacerbate the matter by dictating that probability be learned before statistics, yet this simple concept from statistics requires no probability background, and would help many to understand and produce scientific and data science results.
As discussed previously, a controlled randomized experiment from scratch is the "gold standard". The reason is because if there are confounding variables, individual members of the population expressing those variables are randomly distributed and by the law of large numbers those effects cancel each other out.
Most of the time, though, we do not have the budget or time to conduct a unique experiment for each question we want to investigate. Instead, more typically, we're handed a data set and asked to go and find "actionable insights".
This lands us into the realm of quasi-experimental design (QED). In QED, we can't randomly assign members of the population and then apply or not apply "treatments". (Even in data science when analyzing e.g. server logs, the terminology from the hard sciences holds over: what we might call an "input variable" is instead called the "treatment" (as if medicine were being given to a patient) and what we might call an "output variable" is instead called the "outcome" (did the medicine work?).) In QED, stuff has already happened and all we have is the data.
In QED, to overcome the hurdle of non-random assignment, we perform "matching" as shown below. The first step is to segregate the entire population into "treated" and "untreated". In the example below, the question we are trying to answer is whether Elbonians are less likely to buy. So living in Elbonia (perhaps determined by a MaxMind reverse-IP lookup) is the "treatment", not living in Elbonia is "untreated", and whether or not a sale was made is the "outcome". We have two confounding variables, browser type and OS, and in QED that is what we match on.
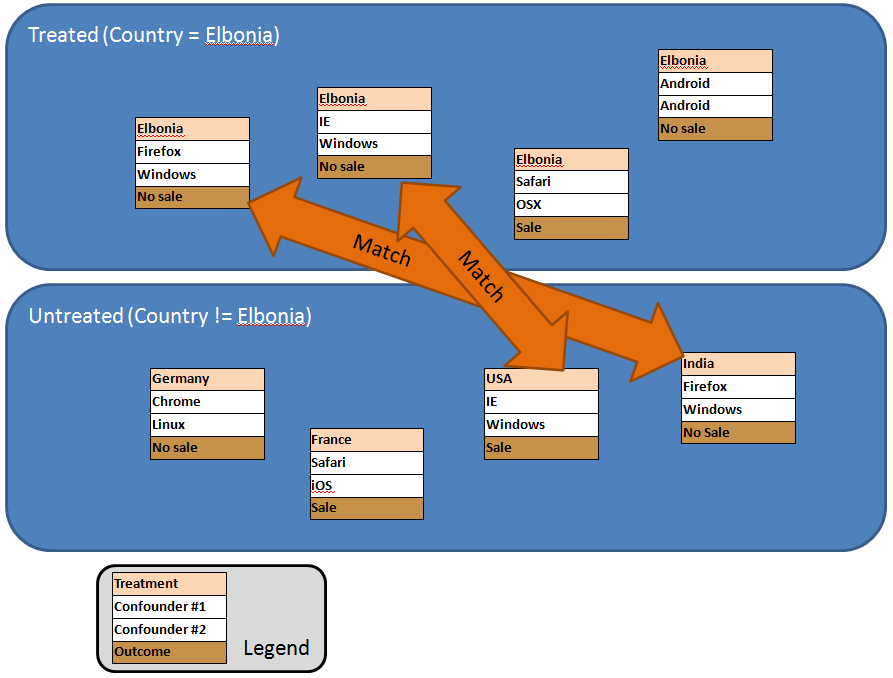
In this way, we are simulating the question, "all else being equal, does living in Elbonia lead to a less likely sale?"
In this process, typically when a match is made between one member of the treated population and one member of the untreated population, both are thrown out, and then the next attempt at a match is made. Now as you can imagine, there are all sorts of algorithms and approaches for what constitutes match (how close a match is required?), the order in which matches are taken, and how the results are finally analyzed. For further study, take a look at the book below just added to the DSA bookstore, Experimental and Quasi-Experimental Designs for Generalized Causal Inference.