
Making Sense of "Making Sense of Performance in Data Analytics Frameworks"

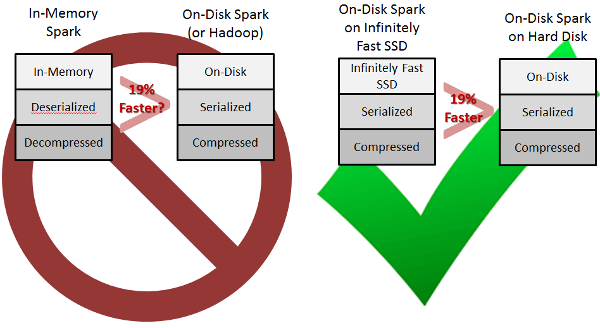
I completely misunderstood Kay Ousterhout's paper Making Sense of Performance in Data Analytics Frameworks to be the comparison on the left. Through a series of e-mails, Kay Ousterhout clarified that the comparison her team drew, regarding the disk performance section of their paper, was (if I now understand correctly) what I've drawn on the right. She wrote to me:
The 19% improvement refers to only the improvement from moving compressed, serialized data from on-disk to in-memory. When you store data in-memory natively with Spark, Spark decompresses and deserializes the data into Java objects, resulting in a much larger improvement; this deserialized and decompressed format is usually what people refer to when they say "In-Memory Spark". (The improvement for the big data benchmark from on-disk Spark to in-memory Spark is quantified here: https://amplab.cs.berkeley.edu/benchmark/). So, you could say "Disk I/O is not the bottleneck for on-disk Spark" or "On-disk Spark could only improve by 19% from optimizing disk I/O". It would also be correct to say that our results imply that Spark using flash would only be at most 19% faster than on-disk Spark (because in that case, the data would still be serialized and compressed).
So the motivation behind their work seems to be, given you have a Spark cluster, what hardware (disk and network) and scheduler/task restructuring changes could you make to improve performance?
Spark is still fast -- many times faster than Hadoop. But the reason it's fast is what is the surprising (to me at least) result determined by the work behind this paper. Spark is fast because data is already deserialized and decompressed. In iterative computations, Spark avoids the serialization/deserialization and compression/decompression round-trips that Hadoop goes through -- at least for data that doesn't go through shuffles. Spark shuffles of course are serialized, and are by default also compressed unless spark.shuffle.compress is set to true.
I apologize to Kay Ousterhout et al for mischaracterizing their results.
(My original blog text titled "Spark Only 19% Faster Than Hadoop?" is below in strike-through.)
That's the conclusion by Kay Ousterhout et al in their new paper Making Sense of Performance in Data Analytics Frameworks. They summarize:
Contrary to our expectations, we find that
(i) CPU (and not I/O) is often the bottleneck,
(ii) improving network performance can improve job completion time by a median of at most 2%, and
(iii) the causes of most stragglers can be identified.
It is, of course, a stark contrast to the 100x improvements claimed in previous years. They pin the bottlenecks on the CPU's involvement in serialization/deserialization and compressing/decompressing formats such as Parquet. Of course, part of the motivation for compressed formats was intentionally to shift the known bottleneck of disk I/O over to the multi-core CPUs which were known to be idle.
Similarly, they pin the lack of reliance on the network on small shuffle sizes. But much work has been done on minimizing shuffle sizes, due to both disk I/O and network bottlenecks.
In my opinion, it raises the question of what the performance would be if we had large memory and fast networks and didn't have to jump through hoops to avoid disk I/O and network bottlenecks. There are confounding issues the paper didn't identify or delve into.
In nothing else, the paper is a refreshing display of academic honesty, as the authors are from UC Berkeley, and Kay Ousterhout is known for her efficient Sparrow scheduler for Spark. Yet this paper minimizes that contribution by finding that handling "straggler" tasks can be better handled via algorithm improvements and identifying other sources of latency such as file system delays.
The paper measures the situation as exists in reality today, and that reality is that so much work has been done to shift the burden away from disk I/O and to minimize shuffle sizes that now Spark's in-memory computing doesn't offer as much of a speedup anymore over naive on-disk Hadoop implementations.
UPDATE 2015-03-19: After more careful re-reading of their paper, it would be more correct to say Spark is 19% faster than Hadoop could potentially be. The exact quote from their paper is: "...improvement [in Spark] came not from eliminating disk I/O, but from other improvements over Hadoop, including eliminating serialization time." So all those "other improvements over Hadoop" that Spark has made relative to Hadoop other than in-memory computing would have to be "backported" to Hadoop in order for Hadoop performance to come within 20% of Spark.